

Welcome to our tutorial on setting up Apache Spark on Ubuntu 23! Whether you’re a data enthusiast or a budding data engineer, Apache Spark is a powerful open-source framework that can supercharge your big data processing tasks. In this guide, we’ll walk you through the installation process, breaking it down into simple steps with examples for newcomers.
Prerequisites
Before we dive into the installation, make sure you have the following prerequisites:
- Ubuntu 23: Ensure you have a clean installation of Ubuntu 23.
- Java Installation: Apache Spark on Ubuntu 23 requires Java to run. Install OpenJDK with the following command:
sudo apt update
sudo apt install openjdk-11-jdk
Step 1: Download Apache Spark on Ubuntu 23
Head over to the official Apache Spark download page and grab the latest version. You can use wget to download it directly to your terminal:
wget https://downloads.apache.org/spark/spark-3.5.1/spark-3.5.1-bin-hadoop3.tgzReplace 3.5.1 with the appropriate version numbers.
Step 2: Extract the Archive
Once the download is complete, extract the Spark archive using the following command:
tar -xvzf spark-3.5.1-bin-hadoop3.tgzAgain, replace 3.5.1 with your version numbers.
Step 3: Move Spark to a Permanent Location
Move the extracted Spark directory to a location of your choice. For example, let’s move it to /opt/:
sudo mv spark-3.5.1-bin-hadoop3 /opt/sparkStep 4: Set Environment Variables
Open your .bashrc file to set up environment variables:
nano ~/.bashrcAdd the following lines at the end of the file:
export SPARK_HOME=/opt/spark
export PATH=$PATH:$SPARK_HOME/bin
export PYSPARK_PYTHON=python3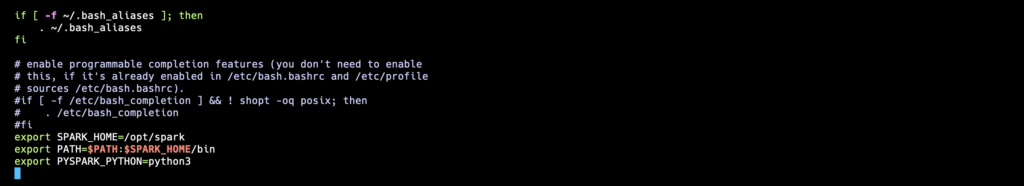
Save the file and execute:
source ~/.bashrcStep 5: Test Your Installation
To ensure that Apache Spark is installed correctly, open a new terminal and run:
spark-shellThis will launch the Spark shell, and you should see the Spark logo with a prompt. You’re now ready to harness the power of Apache Spark on Ubuntu 23!

Spark Context Web UI
The Spark context Web UI is available at http://server_ip:4040. You can access this URL in your web browser to monitor Spark application details, jobs, and stages.
If you want to ensure that your Apache Spark cluster remains active as a service on Ubuntu, you can use a combination of tools like systemd and cron jobs to monitor and restart the Spark processes if needed. Here’s a simple example:
Create a systemd Service:
Create a systemd service file for Apache Spark. Create a file, for example, spark.service, in the /etc/systemd/system/ directory:
[Unit]
Description=Apache Spark
[Service]
Type=simple
ExecStart=/opt/spark/sbin/start-master.sh
Restart=always
RestartSec=3
[Install]
WantedBy=default.targetEnable and Start the Service:
Run the following commands to enable and start the service:
sudo systemctl enable spark
sudo systemctl start sparkThis will start the Spark master as a systemd service.
Create a script, for example, monitor_spark.sh, that checks if Spark is running and restarts it if needed:
#!/bin/bash
SPARK_PID=$(pgrep -f "org.apache.spark.deploy.master.Master")
if [ -z "$SPARK_PID" ]; then
echo "Spark is not running. Restarting..."
/opt/spark/sbin/start-master.sh
else
echo "Spark is running (PID: $SPARK_PID)."
fiMake the script executable:
chmod +x monitor_spark.sh
sh monitor_spark.shsh monitor_spark.sh
Spark is not running. Restarting...
starting org.apache.spark.deploy.master.Master, logging to /opt/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-sysnestor.outsystemctl status spark
● spark.service - Apache Spark
Loaded: loaded (/etc/systemd/system/spark.service; enabled; preset: enabled)
Active: activating (auto-restart) since Sun 2024-03-03 12:28:00 UTC; 292ms ago
Process: 1552923 ExecStart=/opt/spark/sbin/start-master.sh (code=exited, status=0/SUCCESS)
Main PID: 1552923 (code=exited, status=0/SUCCESS)
CPU: 6.338sNavigate to your Apache Spark web console at http://your-ip:8080/
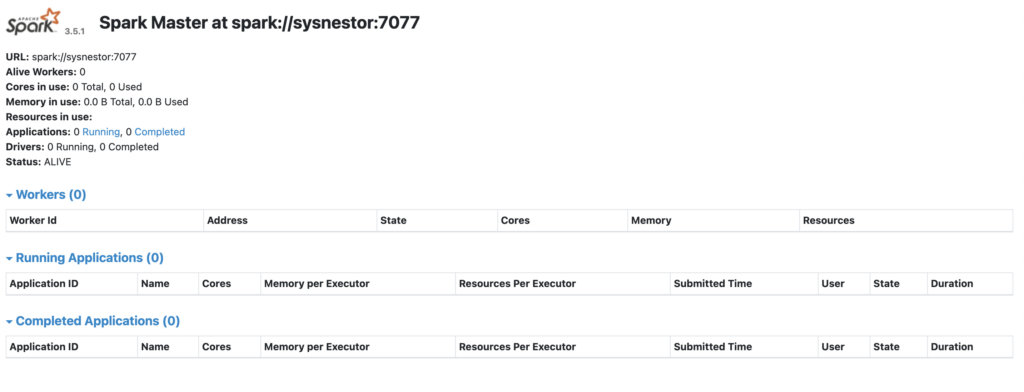
Congratulations! You’ve successfully installed Apache Spark on Ubuntu 23. This guide aimed to make the process accessible for beginners, providing detailed steps and explanations. Feel free to explore Spark’s vast capabilities and integrate it into your data processing projects.
Remember, the world of big data awaits, and Apache Spark is your gateway to unlocking its full potential. Happy coding!
Comments (1)