

Diving into the world of real-time data processing, let’s start with Kafka – a powerhouse in handling vast streams of data. Kafka plays a pivotal role in capturing and making sense of real-time data, acting as the backbone for many applications that require immediate data processing and insights. Its ability to manage high-throughput data has made it indispensable in today’s data-driven landscape.
Switching gears, let’s talk about Kubernetes and its sleek counterpart, K3s. Kubernetes has revolutionized the way we deploy and manage containerized applications, offering scalability and resilience. K3s takes this a step further by being remarkably lightweight, making it a perfect fit for environments like edge computing, Internet of Things (IoT), and Continuous Integration (CI). Its minimal resource requirements without sacrificing functionality is a game-changer for deploying applications in resource-constrained environments.
With this backdrop, our adventure begins. We’re setting out on a journey to marry these two technologies – deploying Kafka within a K3s cluster. Our mission is clear: to walk you through, step by meticulous step, the process of setting up Kafka on K3s. This guide isn’t just about getting things running; it’s about understanding the hows and whys, ensuring you come out the other side with a robust, scalable Kafka setup ready to handle your real-time data needs. Let’s dive in!
Prerequisites
Before we embark on our journey to integrate Kafka with K3s, there are a few essentials you’ll need to have in your toolkit. This preparation is key to ensuring a smooth setup process, allowing you to fully engage with the deployment without unnecessary hiccups.
First off, a comfortable grasp of terminal or command-line interfaces (CLI) is crucial. Whether you’re navigating through directories, executing commands, or configuring settings, the command-line is your bridge to interacting with the underlying systems. If you’re not yet familiar, now’s the perfect time to dip your toes into the basics of CLI operations. There’s a world of resources out there to get you started, from comprehensive guides to quick tutorials.
Next, you’ll need K3s up and running. Whether you choose to set it up on your local machine for a test environment or deploy it on a cloud platform for a more robust setup, the installation process is straightforward. For detailed instructions on getting K3s installed, I recommend visiting the official K3s installation guide. This guide offers a step-by-step breakdown, ensuring you get K3s running smoothly regardless of your setup choice. You can find the guide here: K3s Installation Guide. This link leads to a treasure trove of information, including system requirements, installation options, and troubleshooting tips.
With these prerequisites out of the way, you’re well-prepared to take on the task of deploying Kafka in a K3s environment. Let’s move forward with confidence, knowing our tools and environment are ready for the challenge ahead.
Step 1: Setting Up Your K3s Cluster
You can find the guide here: K3s Installation Guide. This link leads to a treasure trove of information, including system requirements, installation options, and troubleshooting tips.
- Verification: After the installation completes, it’s important to verify that K3s is up and running correctly. Use the
kubectlcommand to check the status of the nodes in your cluster. If K3s has been installed successfully, you should see your node listed as “Ready”.
kubectl get nodes
This command will display the nodes in your cluster, along with their status, roles, age, and version. Seeing your node in a “Ready” state is a green light that your K3s cluster is set up and operational.
By following these steps, you’ve laid the groundwork for your K3s cluster, creating a solid base for deploying applications, including our target for today: Kafka. This lightweight, efficient Kubernetes environment is now poised to host our real-time data processing powerhouse. Let’s proceed with confidence, knowing our foundational K3s setup is ready for the tasks ahead.
Step 2: Understanding Kafka and Its Kubernetes Requirements
As we dive deeper into our journey of deploying Kafka on a K3s cluster, it’s essential to grasp the basics of Kafka’s architecture and its storage needs within a Kubernetes environment. Kafka is a distributed streaming platform that excels in real-time data processing, enabling applications to publish, subscribe to, store, and process streams of records in a fault-tolerant manner.
Kafka Architecture Simplified:
- Brokers: Kafka clusters are composed of one or more servers known as brokers. These brokers manage the storage of messages in topics and serve client requests.
- Topics: A topic is a category or feed name to which records are published. Topics in Kafka are partitioned, meaning a topic can be divided into multiple partitions across multiple brokers to increase scalability and parallelism.
- Producers: Producers are applications or processes that publish (write) records to Kafka topics. They decide which record goes to which partition within a topic.
- Consumers: Consumers are applications or processes that subscribe to topics and process the stream of records produced to them. Consumers can read records from a specific point in the topic and are capable of processing records in parallel.
Storage Requirements for Kafka in Kubernetes:
Kafka requires a robust storage system to ensure the durability and availability of its data. In a Kubernetes environment, this translates to the need for Persistent Volumes (PVs) and Persistent Volume Claims (PVCs). Persistent volumes are essential for Kafka brokers for several reasons:
- Data Durability: Kafka stores a lot of data that must survive pod restarts and failures. Persistent volumes ensure that data is not lost when a pod goes down.
- Performance: Kafka’s performance is heavily dependent on the efficiency of its data storage. Using persistent volumes can help achieve the necessary I/O throughput.
- Scalability: With persistent volumes, you can scale your Kafka deployment up or down without losing data, allowing you to adjust to changing loads.
When planning your Kafka deployment on Kubernetes, consider the following:
- Ensure you provision sufficient persistent storage that matches Kafka’s high throughput and durability requirements.
- Choose the right storage class in Kubernetes that aligns with your performance and availability needs. Storage classes define the type of storage used and can significantly impact the performance of your Kafka cluster.
By understanding Kafka’s architecture and its storage requirements within Kubernetes, you’re better equipped to plan and deploy a Kafka cluster that is robust, scalable, and capable of handling your real-time data processing needs efficiently. With this knowledge in hand, let’s move forward in our deployment process, focusing next on the practical steps to get Kafka up and running on our K3s cluster.
Step 3: Deploying Apache Kafka on K3s
Moving on to the heart of our mission—deploying Kafka on a K3s cluster. For this task, we’ll enlist the help of Helm, a powerful package manager for Kubernetes. Helm simplifies the deployment and management of applications on Kubernetes, allowing you to package, configure, and deploy applications and services with ease. It uses a packaging format called charts, which are collections of files that describe a related set of Kubernetes resources.
Installing Helm:
To get started with Helm, you first need to install it on your system. Helm’s installation script makes this process straightforward. Open your terminal and run the following command:
curl https://raw.githubusercontent.com/helm/helm/master/scripts/get-helm-3 | bashThis command fetches the Helm installation script and executes it, installing the latest version of Helm 3 on your system.
Deploying Apache Kafka Using Helm:
With Helm installed, the next step is to deploy Kafka. We’ll use the Bitnami Kafka chart for this purpose. Bitnami provides a wide range of pre-packaged applications and development stacks, including Kafka, which are easy to install and manage on Kubernetes environments.
Add the Bitnami Charts Repository:
First, add the Bitnami charts repository to your Helm configuration. This step makes the Kafka chart available for installation:

Install Apache Kafka Chart:
Now, deploy Kafka by installing the Bitnami Kafka chart with the following command:
helm install my-kafka bitnami/kafka --set persistence.enabled=true,replicaCount=1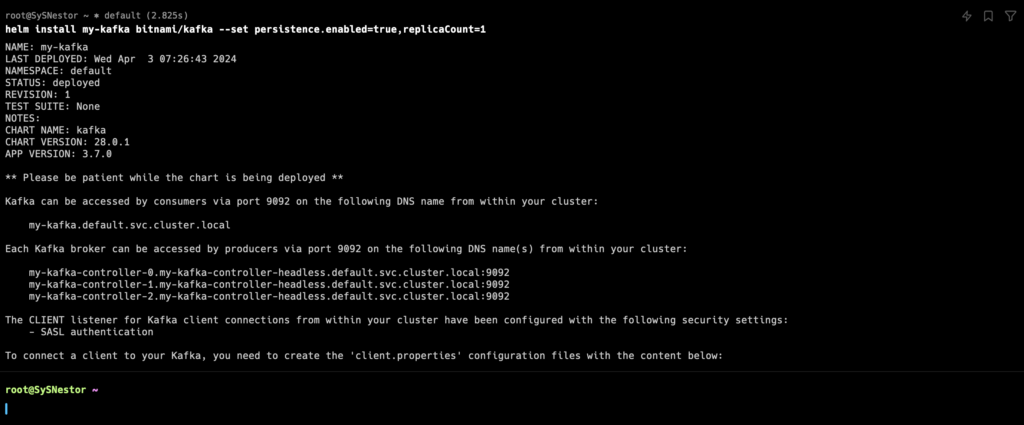
Explanation of Parameters:
- persistence.enabled=true: This parameter enables persistent storage for Kafka. As discussed earlier, Kafka requires durable storage to retain data. Enabling persistence ensures that Kafka data is stored in Persistent Volumes, safeguarding against data loss during pod restarts or failures.
- replicaCount=1: This parameter sets the number of Kafka broker replicas in the cluster. For a development or test environment, a single replica (replicaCount=1) may be sufficient. However, for production environments, you would typically increase this number to ensure high availability and fault tolerance.
Step 4: Verifying Apache Kafka Deployment
After deploying Kafka on your K3s cluster, it’s important to verify that everything is up and running as expected. This verification step ensures that your Kafka cluster is operational and ready to start processing data. Here’s how to check the state of your Kafka pods using kubectl, the command-line tool for interacting with Kubernetes clusters.
Verifying Kafka Pods:
- List the Pods: To check the status of your Kafka pods, use the
kubectl get podscommand. This command lists all the pods in the default namespace, along with their status, age, and other details.
kubectl get pods
- Understanding the Output:
When you run the command, you’ll see output similar to this:
kubectl get pods
NAME READY STATUS RESTARTS AGE
my-kafka-controller-0 1/1 Running 0 159m
my-kafka-controller-2 1/1 Running 0 159m
my-kafka-controller-1 1/1 Running 0 159m- NAME: Shows the name of the pod. Kafka pods will typically have the release name followed by a unique identifier. If Zookeeper is part of your Kafka setup (which is common as Kafka uses Zookeeper for cluster management and coordination), you’ll see Zookeeper pods listed as well.
- READY: Indicates how many containers in the pod are ready. Kafka pods usually contain a single container, so “1/1” means the container in the pod is ready.
- STATUS: The status of the pod. “Running” means the pod has been successfully created and is running without issues.
- RESTARTS: Shows how many times the container in the pod has restarted. Frequent restarts could indicate problems.
- AGE: The age of the pod since it was created.
Expected Outcomes:
- Pods in Running State: Ideally, all your Kafka and associated Zookeeper pods should be in the “Running” state. This indicates they’re operational and ready to handle tasks.
- No Frequent Restarts: The “RESTARTS” count should be low. If you notice a high number of restarts, it might be a sign of issues that need investigating, such as insufficient resources or configuration errors.
Step 5: Accessing Apache Kafka from a Producer or Consumer
Now that your Kafka cluster is up and running on your K3s setup, the next exciting step is to interact with it by publishing and consuming messages. Kafka operates on a simple principle: producers send messages to topics from which consumers read. This model allows for highly scalable and flexible data processing workflows.
Introduction to Apache Kafka Producers and Consumers:
- Kafka Producers are applications or services that produce (send) messages to Kafka topics. Producers can specify which topic they send messages to and can even decide on the partition within the topic, depending on the message key.
- Kafka Consumers are applications or services that consume (read) messages from Kafka topics. Consumers subscribe to one or more topics and process the stream of records produced to them. They can read messages in order or from a specific point in the topic’s history.
Publishing a Message Using a Apache Kafka Producer:
To publish messages, you can run a Kafka producer from within your Kubernetes cluster. Here’s how you can launch a temporary Kafka producer pod and use it to send a message to a topic named “test”.
- Run a Kafka Producer Pod:
kubectl run kafka-producer --restart='Never' --image docker.io/bitnami/kafka:2.6.0 --command -- sleep infinity
This command starts a Kafka producer pod using the Bitnami Kafka image and keeps it alive indefinitely.
- Send a Message to the Kafka Topic:
kubectl exec --tty -i kafka-producer -- kafka-console-producer.sh --broker-list my-kafka:9092 --topic testAfter executing this command, you can type your message into the console. Press Enter to send each message. To exit, use Ctrl+C.
Consuming a Message Using a Kafka Consumer:
Similarly, to read messages from a topic, you can launch a temporary Kafka consumer pod. Here’s how to consume messages from the “test” topic right from the beginning of its log.
- Run a Kafka Consumer Pod:
kubectl run kafka-consumer --restart='Never' --image docker.io/bitnami/kafka:2.6.0 --command -- sleep infinityThis command starts a Kafka consumer pod that remains active indefinitely.
- Consume Messages from the Kafka Topic:
kubectl exec --tty -i kafka-consumer -- kafka-console-consumer.sh --bootstrap-server my-kafka:9092 --topic test --from-beginningThis command will start displaying messages sent to the “test” topic, starting from the oldest. To exit, use Ctrl+C.
Step 6: Tips for Managing and Monitoring Your Kafka Cluster
As you delve into operating your Kafka cluster on K3s, having the right tools for management and monitoring becomes crucial for maintaining performance, ensuring reliability, and troubleshooting potential issues. Kafka, being a distributed system, presents unique challenges that necessitate close attention and effective tools to manage cluster components and data flow seamlessly.
Kafka Management Tools:
- Kafka Manager: Kafka Manager is a web-based tool that allows for comprehensive management and monitoring of Kafka clusters. It provides a user-friendly interface for viewing topic, node, and consumer information, along with the ability to manage topic configurations and partitions. Kafka Manager simplifies the task of managing cluster settings and provides insights into cluster health at a glance.
- Kafdrop: Kafdrop is another web-based UI that serves as an insightful tool for monitoring Kafka topics and browsing consumer groups. It allows users to view Kafka clusters in detail, including the topics, partitions, offsets, and messages. Kafdrop stands out for its simplicity and ease of use, offering a straightforward setup process and intuitive navigation for real-time data visualization and cluster management.
Importance of Monitoring for Performance and Troubleshooting:
- Performance Insights: Monitoring your Kafka cluster provides critical insights into its performance, including throughput, latency, and resource utilization. These metrics are invaluable for ensuring that your cluster is operating efficiently and for identifying bottlenecks or areas that may require scaling or optimization.
- Fault Diagnosis: Effective monitoring tools can help quickly pinpoint issues within your Kafka cluster, such as failed broker nodes, imbalanced partitions, or backlogged consumer groups. Early detection of these problems is essential for minimizing downtime and maintaining a smooth data flow.
- Trend Analysis: Over time, monitoring data can reveal trends in usage and performance, assisting in capacity planning and predictive maintenance. Understanding these trends allows for proactive adjustments to your cluster configuration to handle future demands.
- Alerting: Most monitoring tools offer alerting capabilities, enabling you to receive notifications about critical issues as they arise. This feature is vital for immediate response to potential problems, ensuring high availability and reliability of your Kafka cluster.
Incorporating management and monitoring tools into your Kafka ecosystem not only simplifies administrative tasks but also empowers you with the knowledge and insights needed to maintain a high-performing, reliable streaming platform. Whether you choose Kafka Manager, Kafdrop, or other tools like Confluent Control Center, integrating these solutions into your workflow is a step toward achieving operational excellence with Kafka on K3s.